


With the increasing demand for a platform that is capable of handling data streams and taking instant action on those events, Apache Kafka has emerged as one of the most sought-after open-source messaging technology for event stream processing. It became a popular software platform right after it was made available for distribution after the release of the source code under the license.
You might be benefitting from the existence of this smart software but there’s more to this platform than what you have been plugged into. From building Kafka to its distribution, the journey comprises of everything that the users must be aware of. How one platform changed the shape of the event stream processing is nothing less of a miracle!
What Is Kafka?
Before diving into the journey of this stream-processing software and how it continues to be used by the largest companies and even by the upcoming ones to innovate the various strategies for the data entering their systems, you must know the basics of this platform. So, Apache Kafka was developed with the mission to serve the companies with efficient data pipelines that lead to desired performance after all the successful actions including aggregations, analytics, transformations, enhancements and enrichment, and finally, ingestion in real-time.
This publish-subscribe messaging system provides high throughput and quick processing of a great deal of data messages without any delay. It even adds to the potentiality of certain web-scale Internet companies including Airbnb, LinkedIn, Twitter, and a few others. While the market is full of open-source projects built on a small-scale, Kafka came to light and overpowered.
Kafka Coming To The Fore
This asynchronous messaging technology has great power attached to it and that hasn’t gone unnoticed. Various established firms including the Fortune 100 companies have been trusting Apache Kafka to deal with the data entering their systems and eventually, integrate it efficiently. The tasks performed by this software happen in real-time and that’s what makes it so effective and productive.
According to the statistics gathered over a period of time, Apache Kafka has only grown since its first appearance in the market. The users have been satisfied and impressed by this technology as it has assisted them through the data processes and simplified the further steps in the flow.
Apart from the Internet unicorns, this platform has been a savior for slow-to-evolve enterprises and companies that are aiming to become a leading name in their industry. The graph for the growth of this software has been rising exponentially. The reason for such escalation is the cognizance of data streams and their integration. The companies have understood that for developing the services that can alter the digital scenario, they have to keep track of large amounts of data and integrate it.
The marketing world has been pacing and the expansion has led to the origination of new sources of data. The transactional data that includes inventory, shopping carts, and orders have been amplified with page clicks, searches, “likes,” and recommendations that have become a crucial part of the digital spaces. These factors display a clear picture to the marketing teams regarding their ad campaigns and strategies as they point directly towards the behavior and response of the prospective customers. All this data needs to be analyzed and added to the database for planning the next moves. All the data needs to enter the analytics platforms and move to a differentiator for distinct procedures. Now, Kafka steps in to play its crucial role.
The Dawning Of Kafka At LinkedIn
In 2010, a team at LinkedIn that comprised of Jay Kreps, Jun Rao, and Neha Narkhede built this platform named “Kafka” to ingest the huge amount of event data that may usually encounter a delay due to the rapid changes it undergoes. This was the main issue they focused on while developing Kafka. They wanted the bulk data from the LinkedIn website to be arranged in a lambda architecture that channeled Hadoop and real-time event processing systems. “Real-time” remains under the spotlight here. During that year, such technology that provides a solution for this data entrance in real-time did not exist.
Although the technologies to ingest data into offline batch systems were plenty and performing well, they had a few hiccups that transferred details of implementation to the downstream users. The push model that was incorporated here overwhelmed the customers and led to a few unfavorable instances.
When seeking brilliant delivery guarantees, traditional messaging queues (ActiveMQ, RabbitMQ, etc. come to mind. They even corroborate things like message consumption tracking transactions, protocol mediation, and transactions. However, they possess a destructive capacity for the list of actions that LinkedIn had planned.
There have been constant trials to construct creative machine-learning algorithms and LinkedIn joined this group too. However, the algorithms make no sense and serve no purpose when bereft of data, and initially, receiving the data from the source system and taking it around in a dependable manner was a tough task. The batch processing and enterprise messaging solutions didn’t offer a smooth fix and so, they had to come up with a new trick and hence, a fresh technology.
Kafka had to be a scalable platform and it was designed in a way that would emerge to be the ingestion backbone for the use case it was associated with. After the platform was open-sourced in 2011, it was absorbing 1 billion messages in one day and according to the latest revelations by LinkedIn, it is ingesting 1 trillion messages on a daily basis.
Now that we are acquainted with the emergence and birth story of Kafka, it’s time to understand how it is shaped to deal with all the specific situations in which it is immersed.
Into The Working Of Kafka
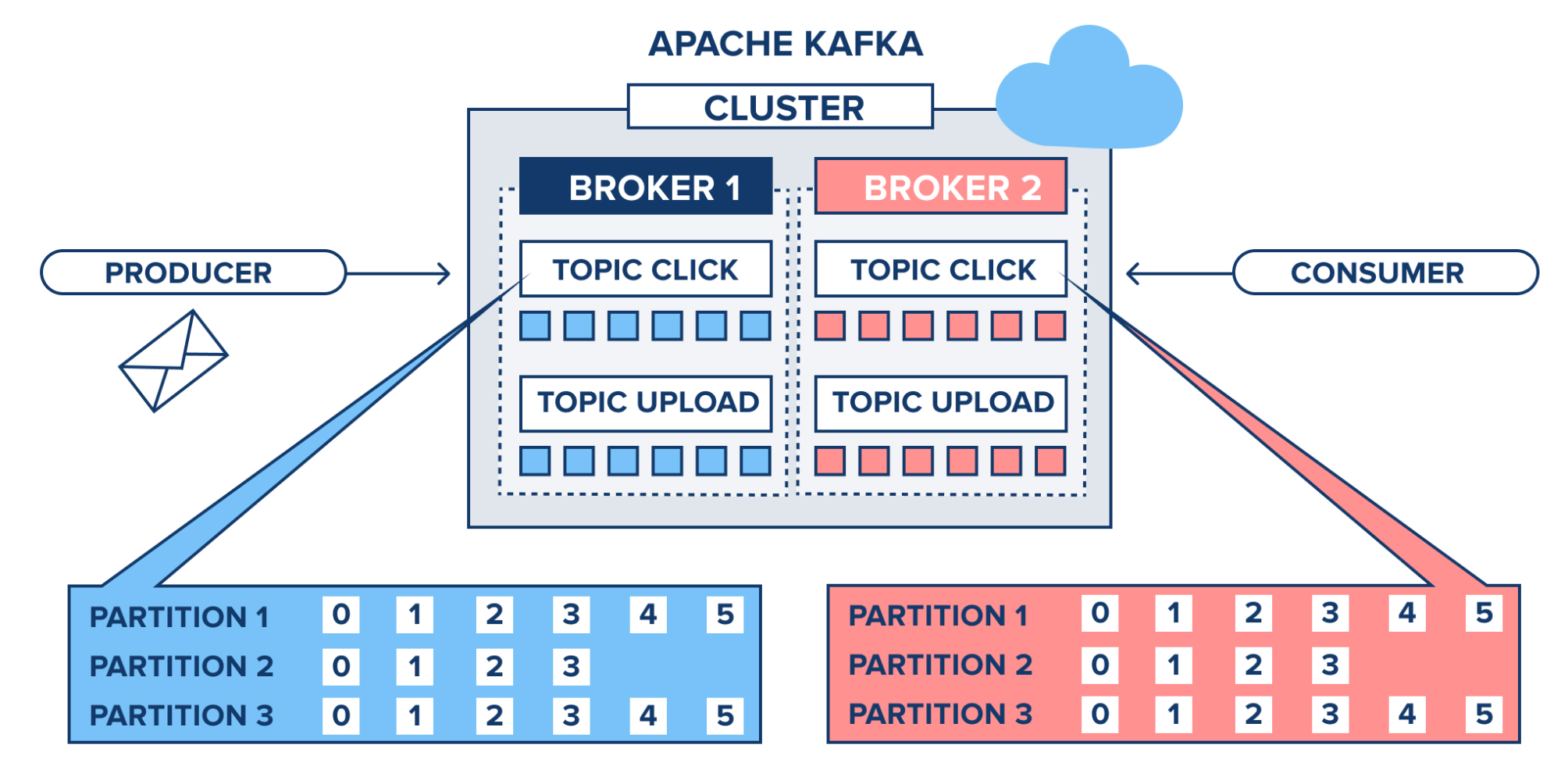
To most of us, Kafka is similar to a Publish/Subscribe pattern that is capable of delivering consistent, scalable, and in-order messaging. This framework comprises of the publishers, topics, and subscribers and has the ability to partition topics and facilitate parallel consumption on a vast scale. Every message that is written to Kafka is prolonged and replicated to peer brokers for fault tolerance. In fact, those messages continue to exist in the system for a programmable amount of time ranging from 7 days to 30 days and more.
The basis of Kafka is the “log”. If being a developer, you find it perplexing, it is because you have application logs running in your mind while reading about this “log” that’s actually supposed to be the key to Kafka. Basically, we are discussing “log data structure” here. So, the log is a manageable storage abstraction that is an append-only and completely ordered set of records wherein data can take any form. In the case of Kafka, it’s inserted as an array of bytes. This definitely would remind you of the basic data structure that holds a database in place because it is built that way.
After databases write change events to a log, they acquire the value of columns from that particular log. In this Kafka platform, the messages are written to a topic which is responsible for maintaining that specific log or multiple logs assigned to each partition. From this, the subscribers are able to read and gain the representation of the data according to their interpretation.
Let’s consider an example revolving around the activity for a shopping cart. A “log” of this activity might have “add item foo,” “add item bar,” “remove item foo,” and “checkout”. The log will perform its duty and make the downstream systems aware of these facts. Now, when a shopping cart service encounters and reads that log, it will be able to derive the cart items that depict what’s in the shopping cart:item “bar” and ready for checkout.
The messages are persisted in Kafka as it can hold them for a good amount of time (maybe forever) and so, applications can backpedal to the previous positions in the reprocess and log. This comes in handy when one wishes to build a fresh application or an analytic algorithm and test it against past actions and events.
Actions That Kafka Doesn’t Perform
Since the log data structure is presented as a first-class citizen, Kafka is quick in responding and acting. It doesn’t work like a traditional message broker that has trappings and appurtenances attached to it.
1. When the messages are written in Kafka, it doesn’t create or have discrete message IDs. Here, when a message is addressed, it is done by their offset in the log.
2. Tracking the messages consumed by the subscribers or the topics that are assigned to the consumers is not what Kafka does. All of these tasks are left for the consumers.
These particular differences between the traditional message brokers and Kafka make the latter ready to make optimizations.
3. Kafka doesn’t stay heavy with all the extra burden of keeping a tab on any indexes that document the messages contained in it. Here, random access doesn’t exist as the consumers receive the messages in order beginning with the offset after they state the offsets.
4. This software platform doesn’t delete. It stores every part of the log for a fixed amount of time.
5. Streaming the messages to the consumers is successfully completed through kernel-level IO by Kafka. It doesn’t buffer the messages in the userspace.
6. Kafka is capable of leveraging the operating system for file page caches and writethrough and writeback to disk.
Kafka Owns A Primary Spot In Big Data Space
The unique built-in features, scalability, and performance characteristics exhibited by Kafka have made this publish-subscribe messaging system own a primary spit in the big data world as an authentic and definitive means to move a copious amount of data at a really high speed.
Initially, the web-scale companies used other options available to deal with the substantial amount of data fed into the system and for its ingestion. However, things changed with the introduction of Apache Kafka. One example of this is Netflix as they began writing their own ingestion framework. In this version, the data was deposited in Amazon S3 and it made use of Hadoop to run batch analytics of UI activities, video streams, performance events, and diagnostic events which in turn directed the user experience feedback.
But with the rise in the demand for real-time analytics, Netflix turned to Kafka and soon, it became its backbone for data ingestion via Java APIs or REST APIs. With Kafka, the Netflix system is able to manage ingestion of approximately 500 billion events each day which almost equals 1.3 PB data. That’s huge! It can control almost 8 million events per second. To route all this data and stack it into back-end data storage including Cassandra and Elastic Search, Netflix has combined Kafka with streaming stacks such as Apache Spark and Apache Samza. This can even load the data into real-time analytics engines directly.
The Newly-Constructed Architecture
The new architecture is a fresh new approach to the lambda architecture or we can say it is an alternative to lambda architecture. People are giving it the name of “kappa architecture”. The integration of Kafka with interactive and supportive tools is being accomplished by open-source developers.
SMACK, one stack is the collection of tools including Cassandra, Apache Spark, Akka, Apache Mesos, and Kafka. SMACK stands for Spark (Streaming – the stream processing system), MESOS (the cluster orchestrator), Akka (the system for providing custom actors for reaction upon the analyses) Cassandra (the storage system and Kafka (publish-subscribe messaging system). After combining all of these, this system implements a type of CQRS (command query responsibility separation). Each of these solutions has a key role to play in the stack.
Kafka As A Support System For Microservices
Kafka has stepped in as a powerful and desired platform for big data ingestion but that’s not all about this software. It even has led to beneficial outcomes for certain applications around the Internet of Things, microservices, and cloud-native architectures on the whole. For a successful implementation of scalable microservices, domain-driven design concepts such as event sourcing and CQRS turn out to be quite helpful mechanisms. Kafka serves as the backing store for such concepts.
When an event sourcing application generates scads of events, it seems to be a challenging task for traditional databases to implement those events. However, Kafka makes it easier, and “log compaction” is another enhancing feature in this platform that is competent to store and preserve events for as long as the application survives. With this feature, the log doesn’t need to be dropped at a preconfigured time duration that ranges from 7 days to 30 days or more. Kafka can manage the whole set of events that have recently and preserve them for all the keys in the set. Consequently, the application becomes loosely coupled as the logs can be discarded and the domain state is restored from a log of the events that are preserved through that additional feature of the platform.
Kafka Versus Traditional Messaging Systems
We have witnessed the development and advancement of technology in various fields of work. Considering the database management systems, it was a striking evolution from RDBMS to specific stores that sorted various things out and smoothened the management process. Similarly, the messaging systems have evolved too. There was a time when “one size fits all” message queues existed but now, there have been gradations in the implementations for problems belonging to various categories. Kafka and traditional messaging have convinced us of their attributes.
The brokers involved in the traditional messaging are advantageous in a way that they help you keep the consumer in a manageable area as they have pure and definite reliability associated with them. The acknowledgment of messages by the consumer is a highly crucial factor and the broker (JMS, AMQP, etc.) steps in here to track those messages. When order processing guarantees are needed and missing the messages can’t be afforded, this lends a helping hand. These traditional brokers implement many protocols (Apache Active MQ implements STOMP, MQTT, AMQP, and more) that are utilized to form a bridge for the components that use distinct protocols.
A few messaging use cases that are valid where Kafka won’t serve a beneficial purpose include request-response messaging, TTLs, correlation ID selectors, non-persistent messaging, and some others.
When, Why, And If You Should Use Kafka…
There are quite a few questions related to Kafka when it comes to incorporating it in your processes. Whether you should use it or skip it for a while – all of this is based on the use cases that you have in mind for the software. It is evident that many established enterprises and web-scale firms have trusted Kafka for a certain class of problems they encounter. However, Kafka isn’t a “one size fits all” as is said for the traditional message broker. If you are aiming at building a set of adaptable and tough data services and applications, Kafka is your solution. It can gather and preserve all the “events” or “facts” for a particular system.
To put in concisely, one has to be well informed about the drawbacks and trade-offs before making a final decision. Having multiple queuing tools and publish/subscribe messaging systems is an important choice to make after contemplating the pros and cons. So, make sure you visualize every scenario and do your research before bringing in new technology for your assistance.
