

For quite a long time, we have been developing systems and working towards making them better. We have been successful in emerging several technologies, architectural patterns, and best practices over the years. One such architectural pattern is Microservices which has developed from the platform of domain-driven design, continuous delivery, platform and infrastructure automation, scalable systems, polyglot programming, and persistence.
What Is A Microservices Architecture?
An American software engineer, Robert C. Martin coined the term single responsibility which postulated that “gather together those things that change for the same reason, and separate those things that change for different reasons.”
A microservices architecture follows the same principle and extends it to the loosely coupled services which can be developed, deployed, and maintained independently. Each of those services is liable for discrete tasks and may communicate with other services through simple APIs to unravel a bigger complex business problem.
What Are The Advantages Of A Microservices Architecture?
Even though the constituent services are small, they will be built by one or more small teams from scratch, separated by service boundaries which make it easier to scale up the development if the necessity arises.
Once you have successfully developed these services, you can deploy them independently of each other and therefore it is easy to spot hot services and scale them independently of the whole application. Microservices also provide you an option for improved fault isolation in accordance with which there is a case of an error in one service the whole application doesn’t compulsorily stop functioning. After the error is fixed, it can be deployed only for the respective service instead of redeploying an entire application.
Another advantage microservices architecture provides you is that it makes it easier to settle on the technology stack (programming languages, databases, etc.) which is best fitted to the specified functionality (service) rather than being required to take a more standardized, one-size-fits-all approach.
Getting Started With Microservices Architecture
Even though microservices architecture has its own set of advantages over traditional architectures yet it doesn’t offer a standard set of principles that you can follow to build a microservices architecture in a better way.
Still, there are some common themes which many organizations that have adopted microservices architectures have followed and which were quite a success for them. Some of those common themes are described below:
1. How To Decompose?
One of the things you can do to make your task easier is to define services corresponding to business capabilities. Business capabilities are the products and services provided by businesses to provide value to their end-users. To identify business capabilities and its corresponding services, you must have a high-level understanding of the business. For example, the business capabilities for an online shopping application might comprise of the following:
- Product Catalog Management
- Inventory Management
- Order Management
- Delivery Management
- User Management
- Product Recommendations
- Product Reviews Management
Once you are able to identify the business capabilities, the required services can be built corresponding to each of these identified business capabilities. Each service can be owned by a different team who are experts in that particular domain and an experienced professional in the technologies that are best suited for those particular services. This results in more stable API boundaries and more stable teams.
2. How To Build And Deploy Services?
After you have finalized the service boundaries of these small services, you can get them developed by one or more small teams using technologies that are best suitable for each purpose. For instance, you can choose to build a User Service in Java with a MySQL database and a Product Recommendation Service with Scala/Spark.
When developed, CI/CD pipelines are often found out with any of the available CI servers (Jenkins, TeamCity, Go, etc.) to run the high-quality automated test cases and to deploy these services independently to different environments (Integration, QA, Staging, Production, etc).
3. Be Careful While Designing The Individual Services
When you are designing the services, you have to be careful while defining them and brainstorm about what will be exposed, what protocols will be used to interact with the service, etc.
It is very paramount to conceal any complexity and implementation details of the service and only expose what is required by the service’s clients. If unnecessary details are exposed, it becomes very complicated and difficult to change the service later as there will be a lot of diligent work to determine who is depending on the various parts of the service.
In addition to this, a huge amount of flexibility is lost while deploying the service independently.
The following diagram reveals the most common mistakes people do while designing microservice:
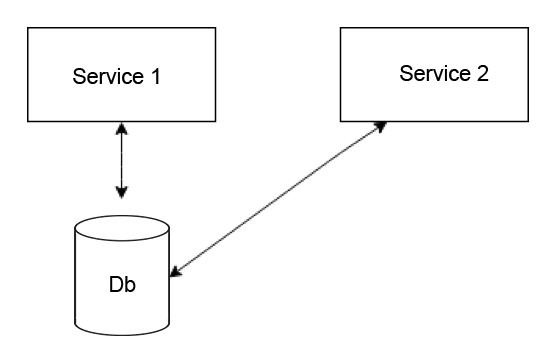
Looking at the diagram you can see that we are taking a service (Service 1) and storing all of the information needed by the service into a database. When another service (Service 2) is created which requires that same data, we access that data directly from the database.
This approach might seem logical and appropriate in certain cases- maybe it is easy to access data in a SQL database or write data to a SQL database or maybe the APIs needed by Service 2 is not easily available.
The moment this approach is adopted, you immediately lose control in determining what is hidden and what is not. Afterward, if the schema needs to be changed, the flexibility to make that change is lost, since you won’t know who is using the database and whether the change will break Service 2 or not.
An alternative and right way to tackle this is showcased below:
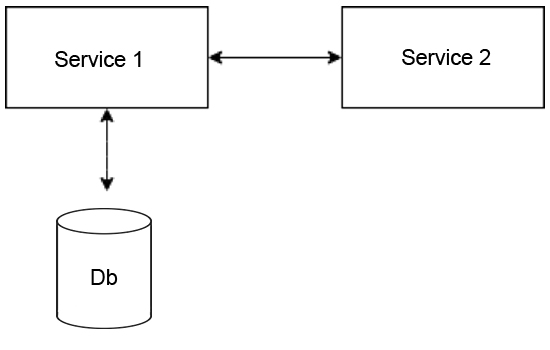
Service 2 should avoid going directly to the database and instead access Service 1, hence, preserving absolute flexibility for various schema changes that may be required. Now, you do not need to worry about other parts of the system but only if you make sure that tests for exposed APIs pass.
As specified, you would like to settle on the protocols for communication between services carefully. For instance, if Java RMI is chosen, not only is that the user of the API restricted to employing a JVM based language, but additionally, the protocol in and of itself is sort of brittle because it’s difficult to take care of backward compatibility with the API.
Finally, when you are providing client libraries to clients for them to use the service, think about it carefully, because it is best to avoid repeating the integration code. If you end up making this mistake, it can restrict changes from being made in the API if the clients rely on unnecessary details.
4. Decentralize Actions
Many organizations have followed a model where the teams who build the services take care of everything related to the services and found it successful for themselves. In such a model, a team is responsible to develop, deploy, maintain, and support the services. No separate teams are required for support and maintenance.
You can achieve the same results with an open-source model as well. In this approach, the developer who needs to make changes in service can check out the code, work on a feature, and submit a PR himself instead of waiting for the service owner to pick up and work on the required changes.
But for this model to work efficiently, you will need proper technical documentation along with setup instructions and guidance for each service so that it is easy for anyone to pick up and work on the service.
Another benefit of this approach is that it keeps developers laser-focused on writing high-quality code as they are aware that others will be looking at it.
Some alternative architectural patterns can help in decentralizing things. For instance, you would possibly have an architecture where the collection of services are communicating via a central message bus.
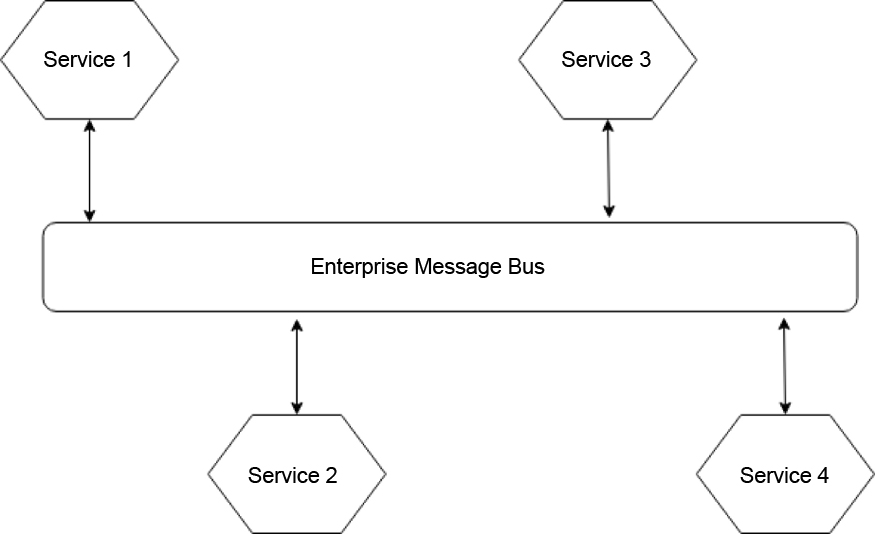
This bus is responsible to handle the routing of messages from different services. Message brokers such as RabbitMQ can be taken as an example here.
Often, people start putting extra logic into the central bus and it begins to know more about your domain. As it becomes more intelligent and aware, it can pose a problem as it becomes extremely difficult to make changes that require coordination across separate dedicated teams.
Thus, it is advised that you should not give much information to such architectures and let them just handle the routing. Event-based architectures are best suited in such scenarios.
5. Deploy
It is vital to write Consumer-Driven Contracts for any API that is being depended upon. This is to make sure that new changes in that API don’t break your API.
In Consumer Driven Contracts, each consumer API captivates their expectation of the provider in a separate contract. All these contracts are shared with the provider so that they can get insights into the requirements they must fulfill for each client.
You must ensure that Consumer Driven Contracts must pass completely before being deployed and before any changes are introduced to the API. Moreover, it helps the provider to know what services are depending on it and how other services are depending on it.
There are two common models to help you in deploying independent microservices.
Multiple Microservices Per Operating System
Firstly, multiple microservices per operating system can be deployed. This model is time-saving in automating certain things, for example, the host for each service doesn’t have to be provisioned.
A major drawback of this approach is that it limits the ability to change and scale services independently. It also creates difficulty in managing dependencies. For example, all the services on the same host will have to use the same version of Java if they are written in Java. Moreover, these independent services can produce undesirable side effects for other running services which can be an extremely challenging problem to reproduce and solve.
One Microservice Per Operating System
To overcome the challenges posed by the first model, the second model comes to your rescue where one microservice per operating system is deployed.
With this model, the service is more isolated and therefore to efficiently manage dependencies and scale services independently. Moreover, it isn’t expensive either.
Traditionally, this problem was solved with Hypervisors whereby multiple virtual machines are provisioned on the same host. Such an approach isn’t cost-effective as the hypervisor process itself consumes some resources and, obviously, the more VMs that are provisioned, the more resources will be consumed. And that is where the container model gets good traction and is given priority. One implementation of that model is Docker.
How To Make Changes To Existing Microservice APIs While In Production?
Determining the ways to make changes in existing microservice APIs when others are using them in production is another challenge faced with a microservices model. Making changes to the microservice API might result in breaking of the microservice which is dependent on it.
However, this problem can be solved using various methods.
Firstly, version your API and when changes are required for the API, deploy the new version of the API while still keeping the first version up. Then the dependent services can be upgraded at their own pace to use the newer version. When all of the dependent services are migrated to use the new version of the changed microservice, it can be brought down.
A major drawback of this approach is that it becomes difficult to maintain the various versions. If any new changes or bug fixes have to be made, then they must be done in both versions.
This is the reason why an alternative approach can be considered in which another endpoint is implemented in the same service when the changes are needed. Once the new endpoint is being fully utilized by all services, then the previous endpoint can be deleted.
One noticeable advantage to this approach is that it is easier to maintain the service as there will always be only one version of the API running.
6. Making Standards
When multiple teams are working on services independently, it is best to introduce some standards and best practices, such as error handling. As it is obvious, each service would likely handle errors differently, and there is no doubt a notable amount of unnecessary code would be written.
Introducing standards always come in handy in the long run. It is also paramount to let others know what an API does and documentation of the API should always be done when creating it. Tools such as Swagger are very useful in assisting in development across the entire API lifecycle, from design and documentation, to test and deployment. When you create metadata for your API and let users play with it, it lets them know more about it and use it more efficiently.
Service Dependencies
In the case of microservices architecture, over a period of time, each service starts depending on more and more services. This can lead to more problems as the services grow, for example, the number of service instances and their location (host+port) might change drastically. Moreover, the protocols and the format in which data is shared might differ from service to service.
This is where API Gateways and Service Discovery become very useful. Implementing an API Gateway becomes a single entry point for all clients, and API Gateway can expose a different API for each client.
The API gateway might also implement security such as verifying whether the client is authorized to perform the request or not. There are some tools like Zookeeper which can be used for Service Discovery (even though it was not built for that purpose). There are many more present-day tools such as etcd and Hashicorp’s Consul which treat Service Discovery as first-class citizens and they are surely worth looking at for this problem.
7. Failure
An important thing to keep in mind is that microservices are not resilient by fault. There are going to be failures in services. This can happen because of failures in dependent services. Moreover, failures can arise for a variety of reasons such as bugs in code, network timeouts, etc.
The most critical thing when it comes to a microservices architecture is to ensure that the whole system is not impacted or goes down when there are errors in an individual part of the system.
Patterns like Bulkhead and Circuits Breaker can assist you to achieve better resilience.
Bulkhead
The Bulkhead pattern works in a way in which it isolates elements of an application into pools so that if in case of failure of one, the others continue to function. The pattern is termed Bulkhead because it resembles the sectioned partitions of a ship’s hull. If the hull of a ship is compromised, only that damaged section fills with water, which further prevents the ship from sinking.
Circuit Breaker
The Circuit Breaker pattern works on the principle which wraps a protected function call in a circuit breaker object which monitors for failures. Once a failure crosses its threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all for a certain configured timeout.
After the timeout expires, the circuit breaker permits some calls to pass through, and if they are successful the circuit breaker resumes a normal state. For the time period the circuit breaker has failed, users can be notified that a certain part of the system is broken and the rest of the system can still be used.
You need to be cautious because providing the required level of resiliency for an application can be a multi-dimensional challenge.
8. Monitoring And Logging
Distribution in microservices is based on nature and monitoring and logging of individual services can pose a challenge. It gets difficult to go through and correlate logs of each service instance and figure out individual errors. Just like the monolithic applications, there is no single place to monitor microservices.
Log Aggregation
To come to a solution to such problems, a preferred approach is to take advantage of a centralized logging service that aggregates logs from each service instance. Users can search through these logs from one centralized spot and configure alerts when certain messages appear.
There are standard tools that are available and extensively used by various enterprises. The most common and frequently used solution in which logging daemon and Logstash collects and aggregates logs which can be searched via the Kibana dashboard indexed by Elasticsearch.
Stats Aggregation
Equivalent to log aggregation, stats aggregation such as CPU and memory usage can also be leveraged and stored centrally. Certain tools like Graphite do an excellent job in pushing to a central repository and storing efficiently.
In situations where one of the downstream services becomes incapable of handling requests, there needs to be a way to trigger an alert and that is where implementing health check APIs in each service becomes important- they return information on the health of the system.
A health check client, which could be a monitoring service or a load balancer, invokes the endpoint to check the health of the service instance periodically in a certain time frame. Even though all of the downstream services are healthy, there could still be a downstream communication problem between services. Netflix Hystrix project is one such tool that enables an ability to identify such types of problems.
